
About me
I am a research fellow at the Huazhong University of Science and Technology (华中科技大学), in the HUST Media Lab (智能媒体计算与网络安全实验室), collaborating with Prof. Junqing Yu (于俊清). I major in Computer Science and my research interests lie in the areas of computer vision, multimedia models, motion estimation, and social media analysis.
News
- 2026.2: Our Three papers are accepted to CVPR'26, congrating to Sichen.
- 2026.1: Our paper on LLM tuning is accepted to ICLR'26, congrating to Wenbing.
- 2025.6: We won 1st place in the Video Track and 3rd place in the Image Track at the 2025 ACM MM Social Media Prediction Challenge!.
- 2025.6: Our Two papers on Medical Learning is accepted to MICCAI'25, congrating to Qillong.
- 2025.5: Our paper on Social Analysis is accepted to ACL'25, congrating to Yunyao.
- 2025.4: Our paper on 3D learning is accepted to IJCAI'25, congrating to Youjia.
- 2025.3: Our paper on medical learning is accepted to ICME'25, congrating to Qilong.
- 2025.2: Our Two papers on VLLM/3D are accepted to CVPR'25, congrating to Yangliu and Youjia.
- 2025.2: Our paper on MLLM is accepted to ICLR'25 Spotlight, congrating to Luo Run.
- 2024.12: Our Two papers on Tracking/Anomaly Detection are accepted to AAAI'25, congrating to Zhou Hang.
- 2024.9: Our paper on Multimodal Tech is accepted to NeurIPS'24, congrating to Wenbing.
- 2024.7: Our paper on Point Tracking is accepted to ACM MM'24.
- 2024.3: Our paper on Feature Compress is accepted to ICME'24, congrating to Tang Ying
- 2023.12: Our paper on Tracking is accepted to AAAI'24, congrating to Luo Run.
- 2022.12: Our paper on Tracking is accepted to AAAI'23.
- 2022.2: Our paper on Tracking is accepted to CVPR'22.
- 2021.8: Our paper on Tracking is accepted to ICMR'21.
Experience
- B.S. in University of Electronic Science and Technology of China (电子科技大学), 2012~2016
- M.S. in Huazhong University of Science and Technology (华中科技大学), 2016~2019
- Ph.D in Huazhong University of Science and Technology (华中科技大学), 2019~2023
- Research Fellow in National University of Singapore (NUS), 2025~2026
Award and Service
- ACM Outstanding Student
- Outstanding Doctoral Scholarship
- Conference Reviewers: CVPR23/24/25/26, ICCV23/25, ECCV24/26, ICML26, ACL26, AAAI24/25/26, NIPS24/25, ICLR25, ACM MM24/25, IJCAI24/25
- Journal Reviewers: TIP, PR, TCSVT, TMM, KBS, SIGPRO
Publications (full list)
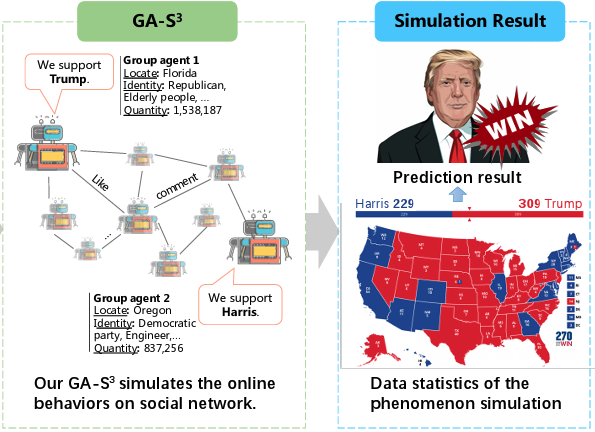 | GA-S3: Comprehensive Social Network Simulation with Group Agents Yunyao Zhang, Zikai Song*, Hang Zhou, Wenfeng Ren, Yi-Ping Phoebe Chen, Junqing Yu, Wei Yang ACL findings, 2025 paper / code In this study, we propose a comprehensive Social network Simulation System that leverages newly designed Group Agents to make intelligent decisions regarding various online events. |
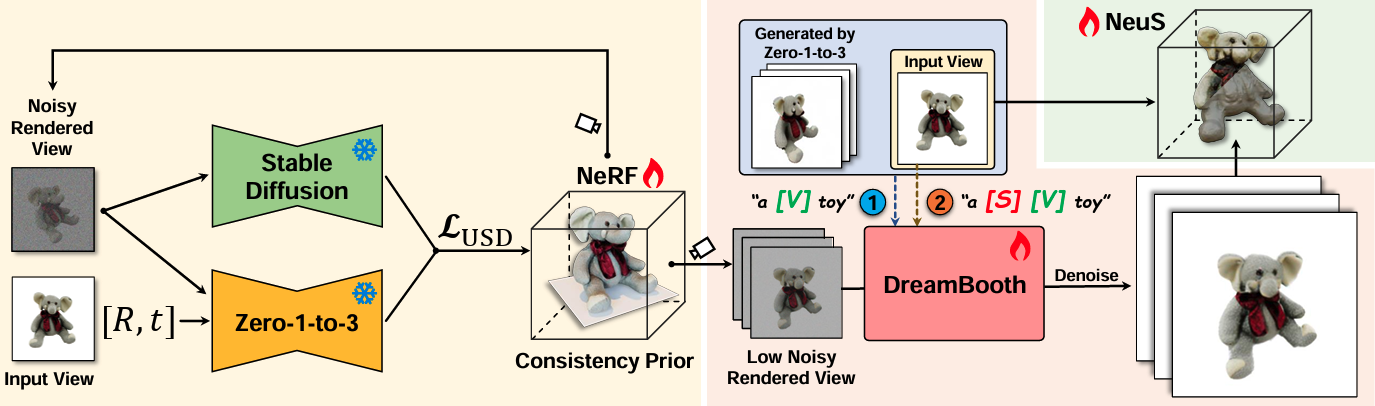 | Optimized View and Geometry Distillation from Multi-view Diffuser Youjia Zhang, Zikai Song, Junqing Yu, Yawei Luo, Wei Yang* IJCAI,2025 paper / code We introduce an Unbiased Score Distillation (USD) that utilizes unconditioned noises from a 2D diffusion model, greatly refining the radiance field fidelity. |
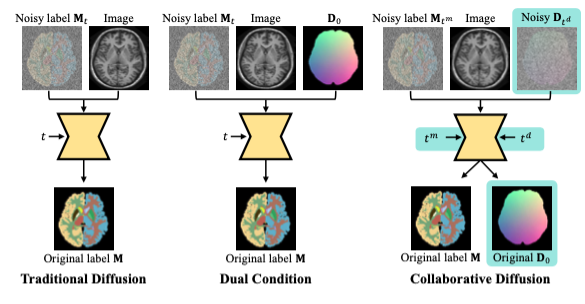 | CA-Diff: Collaborative Anatomy Diffusion for Brain Tissue Segmentation Qilong Xing, Zikai Song*, Yuteng Ye, Yuke Chen, Youjia Zhang, Na Feng, Junqing Yu, Wei Yang* ICME,2025 paper / code We propose Collaborative Anatomy Diffusion (CA-Diff), a framework integrating spatial anatomical features to enhance segmentation accuracy of the diffusion model. |
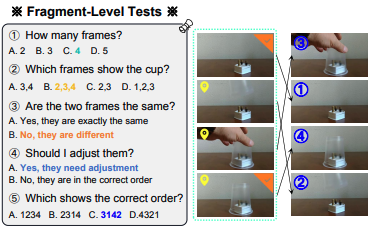 | SF2T: Self-supervised Fragment Finetuning of Video-LLMs for Fine-Grained Understanding Yangliu Hu, Zikai Song*, Na Feng, Yawei Luo, Junqing Yu, Yi-Ping Phoebe Chen, Wei Yang* CVPR,2025 paper / code We propose a Self-Supervised Fragment FineTuning (SF2T), a novel effortless fine-tuning method, employs the rich inherent characteristics of videos for training, while unlocking more fine-grained understanding ability of Video-LLMs. |
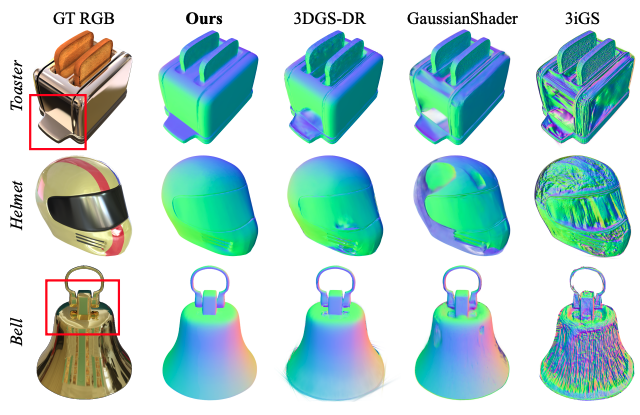 | Ref-GS: Directional Factorization for 2D Gaussian Splatting Youjia Zhang, Anpei Chen, Yumin Wan, Zikai Song, Junqing Yu, Yawei Luo, Wei Yang* CVPR,2025 paper / code We introduce Ref-GS, a novel approach for directional light factorization in 2D Gaussian splatting, which enables photorealistic view-dependent appearance rendering and precise geometry recovery. |
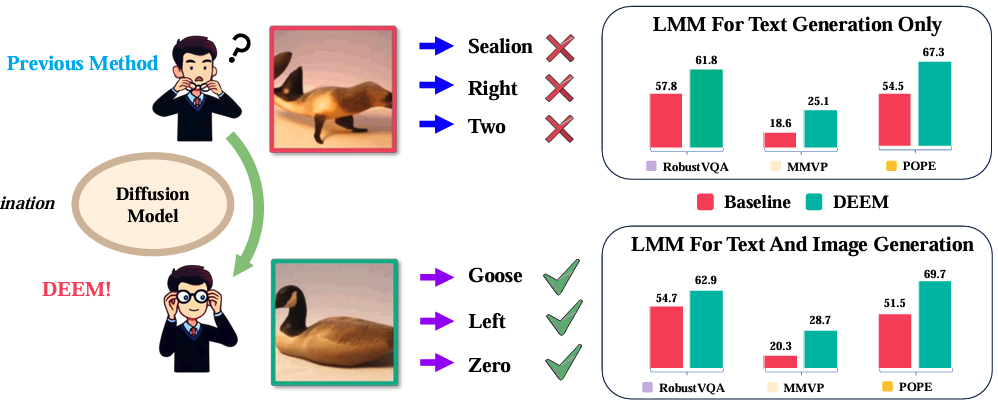 | Deem: Diffusion models serve as the eyes of large language models for image perception Run Luo, Yunshui Li, Longze Chen, Wanwei He, Ting-En Lin, Ziqiang Liu, Lei Zhang, Zikai Song, Xiaobo Xia, Tongliang Liu, Min Yang, Binyuan Hui ICLR,2025 (Spotlight) paper / code We propose DEEM, a simple but effective approach that utilizes the generative feedback of diffusion models to align the semantic distributions of the image encoder. |
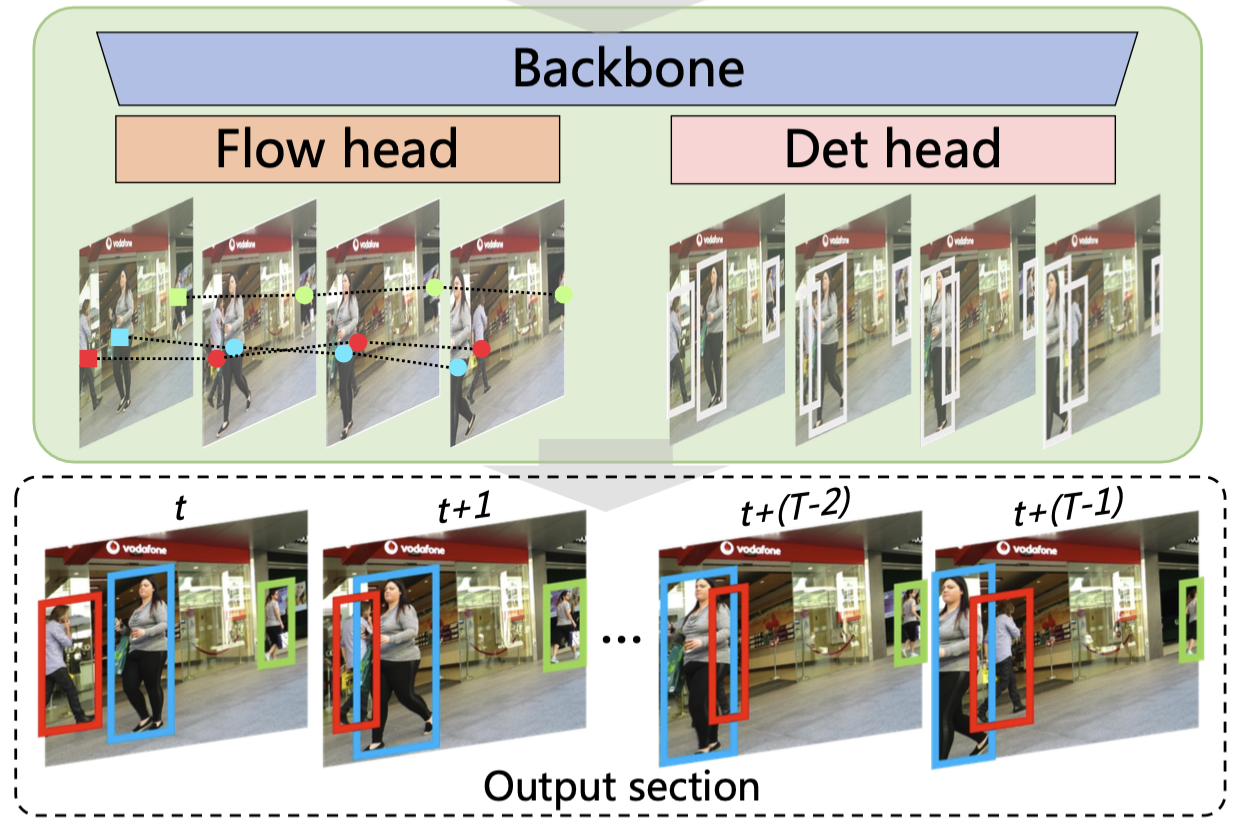 | Temporal Coherent Object Flow for Multi-Object Tracking Zikai Song, Run Luo, Lintao Ma, Ying Tang, Yi-Ping Phoebe Chen, Junqing Yu, Wei Yang* AAAI,2025 paper / code We propose a section-based multi-object tracking approach that integrates a temporal coherent Object Flow Tracker, capable of achieving simultaneous multi-frame tracking by treating multiple consecutive frames as the basic processing unit, denoted as a “section”. |
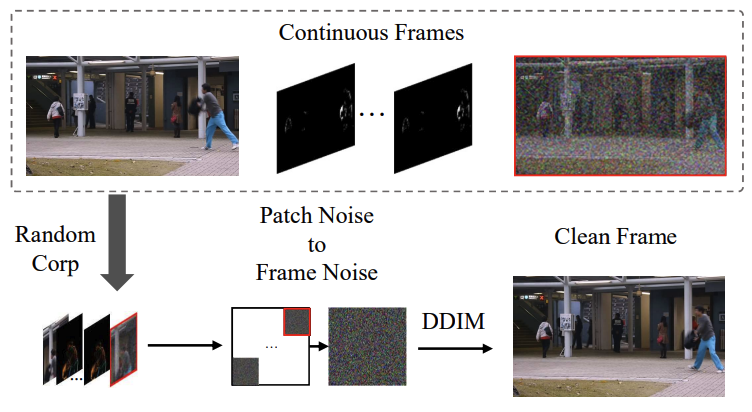 | Video Anomaly Detection with Motion and Appearance Guided Patch Diffusion Model Hang Zhou, Cai Jiale, Yuteng Ye, Yonghui Feng, Chenxing Gao, Junqing Yu, Zikai Song*, Wei Yang AAAI,2025 paper / code We introduce innovative motion and appearance conditions that are seamlessly integrated into our patch diffusion model. |
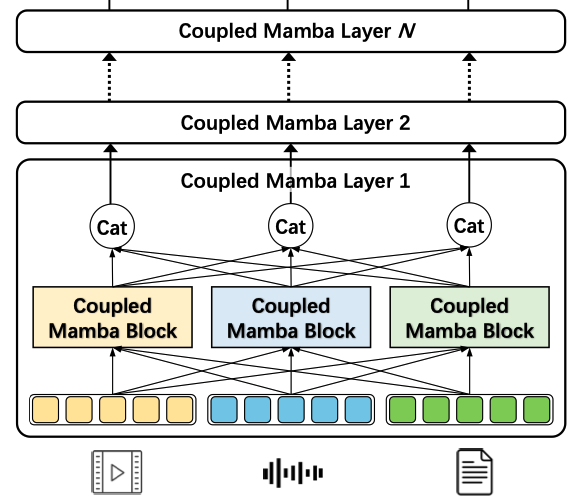 | Coupled Mamba: Enhanced Multimodal Fusion with Coupled State Space Model Wenbing Li, Hang Zhou, Junqing Yu, Zikai Song*, Wei Yang* NeurIPS,2024 paper / code We propose the Coupled SSM model, for coupling state chains of multiple modalities while maintaining independence of intra-modality state processes. |
 | Autogenic Language Embedding for Coherent Point Tracking Zikai Song, Ying Tang, Run Luo, Lintao Ma, Junqing Yu, Yi-Ping Phoebe Chen, Wei Yang* ACM MM,2024 paper We introduce a novel approach leveraging language embeddings to enhance the coherence of frame-wise visual features related to the same object. |
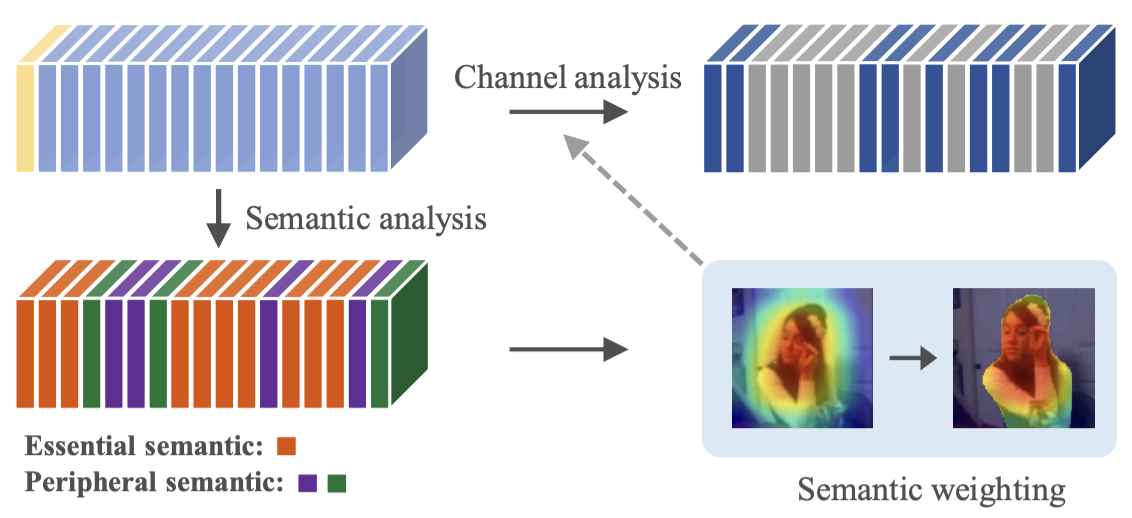 | Agnostic Feature Compression with Semantic Guided Channel Importance Analysis Ying Tang, Wei Yang, Junqing Yu, Zikai Song* ICME,2024 paper We can apply compression operation to a deeper degree for less irrelevant parts to achieve a high compression rate, while preserving the performance by applying a lower compression ratio to the more important parts. |
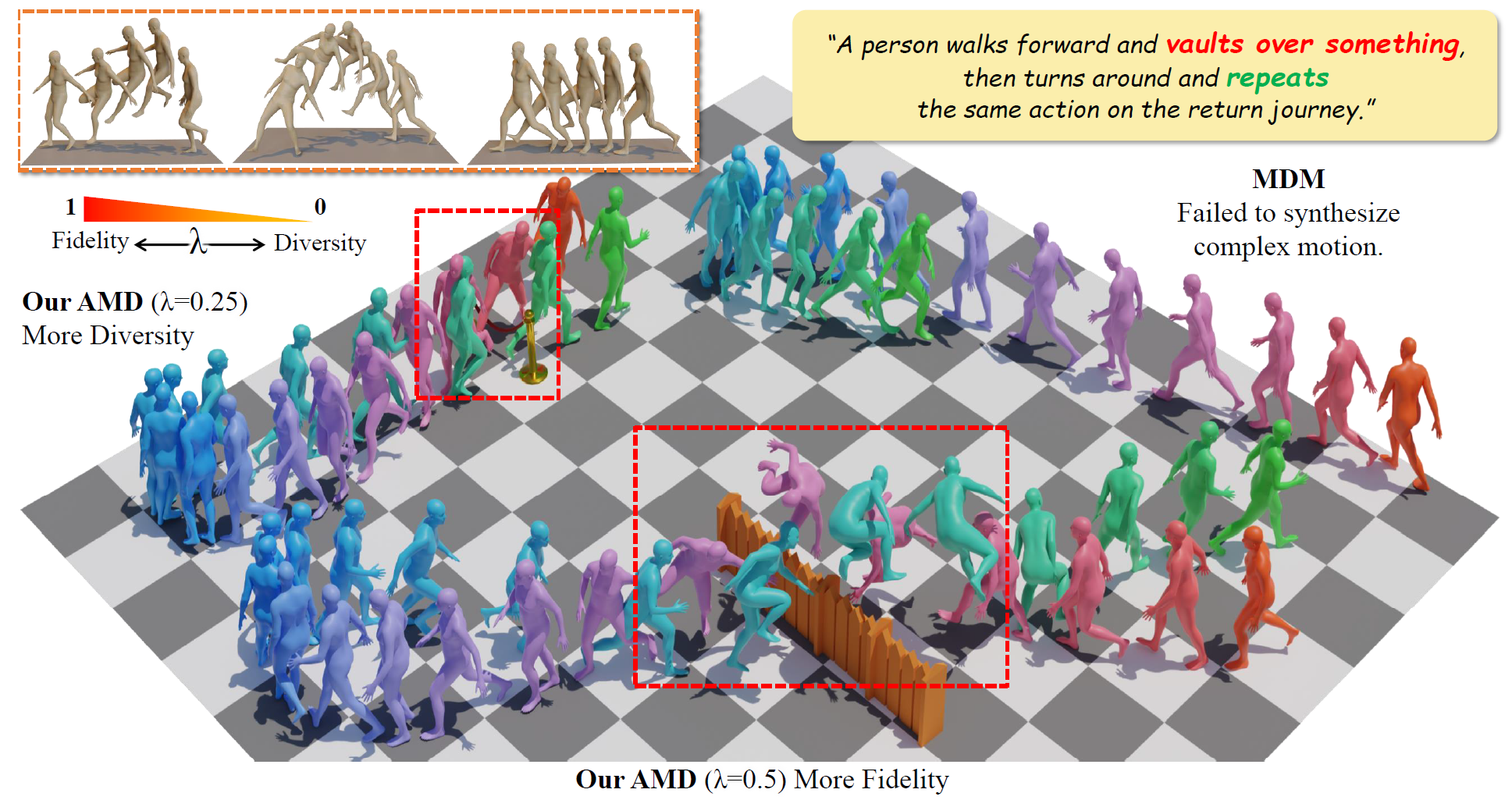 | AMD: Anatomical Motion Diffusion with Interpretable Motion Decomposition and Fusion Beibei Jing, Youjia Zhang, Zikai Song, Junqing Yu, Wei Yang* AAAI,2024 arXiv We propose the Adaptable Motion Diffusion (AMD) model, which leverages a Large Language Model (LLM) to parse the input text into a sequence of concise and interpretable anatomical scripts that correspond to the target motion. |
 | Progressive Text-to-Image Diffusion with Soft Latent Direction Yuteng Ye, Jiale Cai, Hang Zhou, Guanwen Li, Youjia Zhang, Zikai Song, Chenxing Gao, Junqing Yu, Wei Yang* AAAI,2024 arXiv / code We propose to harness the capabilities of a Large Language Model (LLM) to decompose text descriptions into coherent directives adhering to stringent formats and progressively generate the target image. |
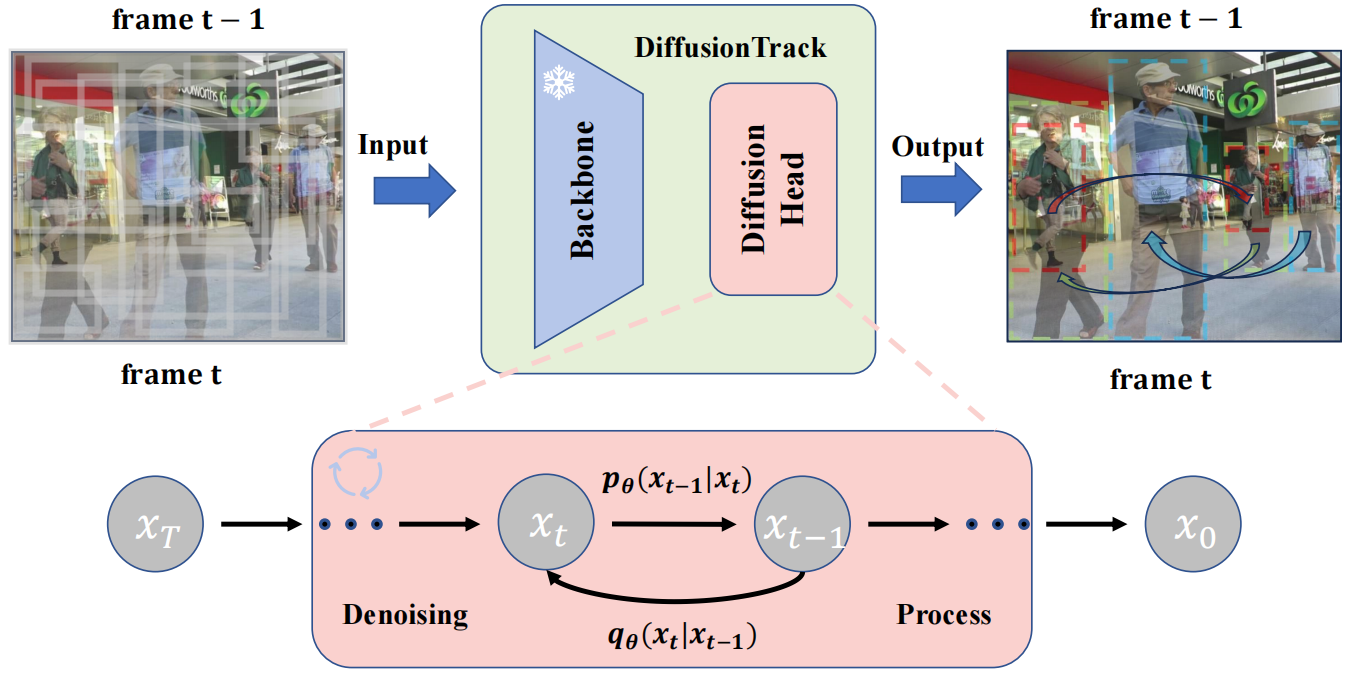 | DiffusionTrack: Diffusion Model For Multi-Object Tracking Run Luo, Zikai Song*, Lintao Ma, Jinlin Wei, Wei Yang, Min Yang* AAAI,2024 arXiv / code We formulates object detection and association jointly as a consistent denoising diffusion process from paired noise boxes to paired ground-truth boxes. |
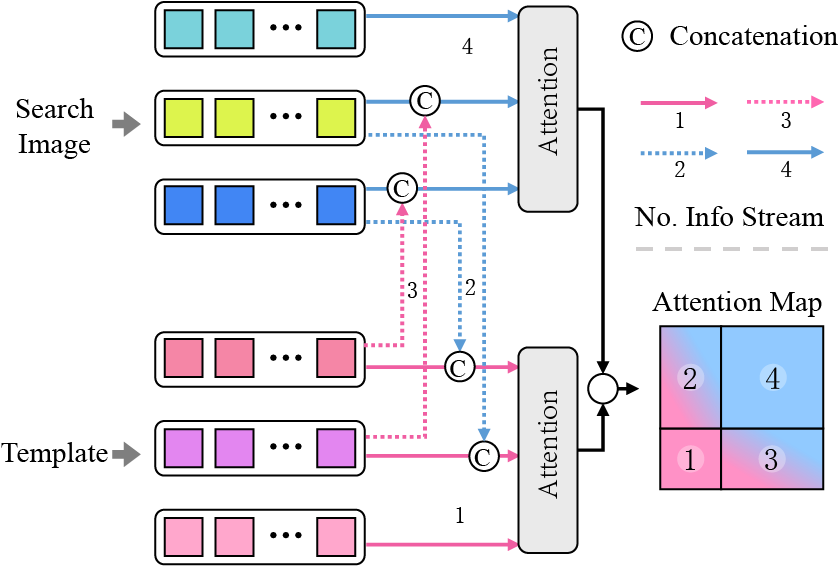 | Compact Transformer Tracker with Correlative Masked Modeling Zikai Song, Run Luo, Junqing Yu*, Yi-Ping Phoebe Chen, Wei Yang* AAAI,2023 (Oral Presentation) arXiv / code We demonstrate the basic vision transformer (ViT) architecture is sufficient for visual tracking with correlative masked modeling for information aggregation enhancement. |
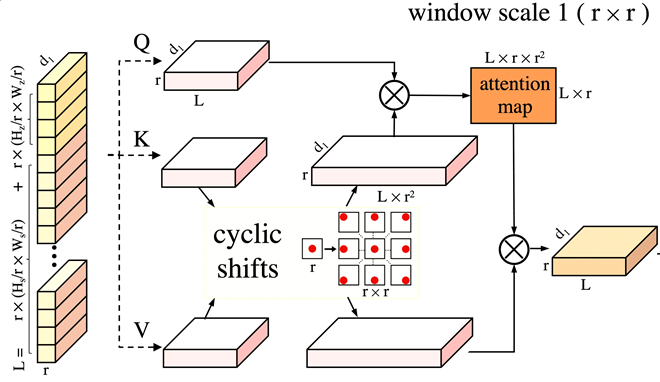 | Transformer Tracking with Cyclic Shifting Window Attention Zikai Song, Junqing Yu*, Yi-Ping Phoebe Chen, Wei Yang CVPR, 2022 arXiv / code CSWinTT is a new transformer architecture with multi-scale cyclic shifting window attention for visual object tracking, elevating the attention from pixel to window level. |
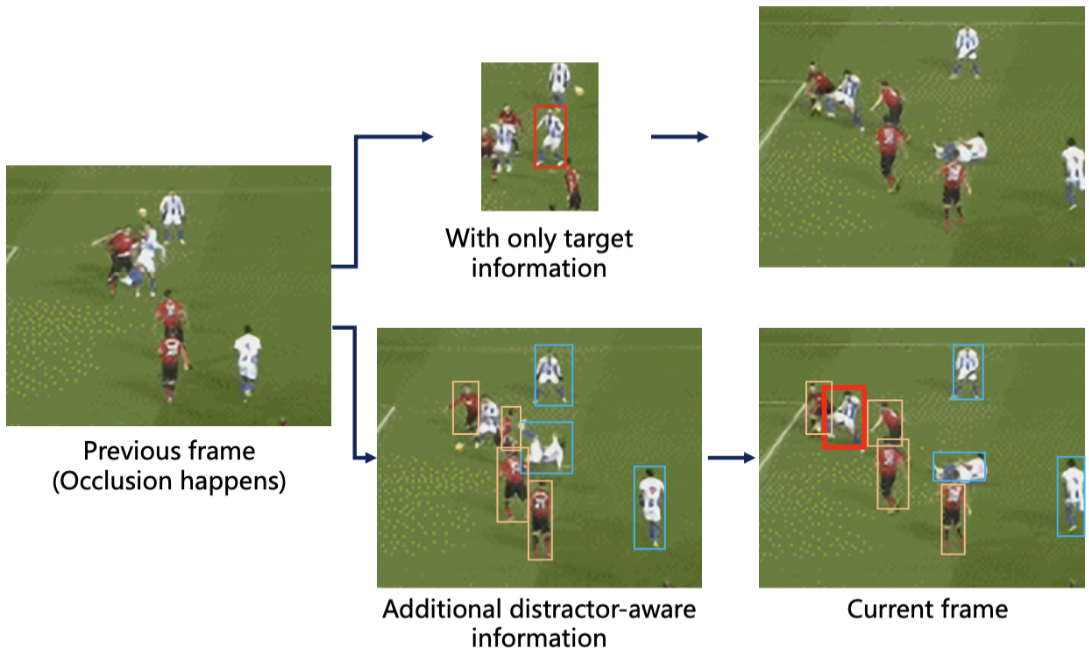 | Distractor-Aware Tracker with a Domain-Special Optimized Benchmark for Soccer Player Tracking Zikai Song, Zhiwen Wan, Wei Yuan, Ying Tang, Junqing Yu, Yi-Ping Phoebe Chen ICMR, 2021 Project Page / paper We proposed a distractor-aware player tracking algorithm and a high-quality benchmark for soccer play tracking, deal with occlusion and similar distractors in soccer scenes. |
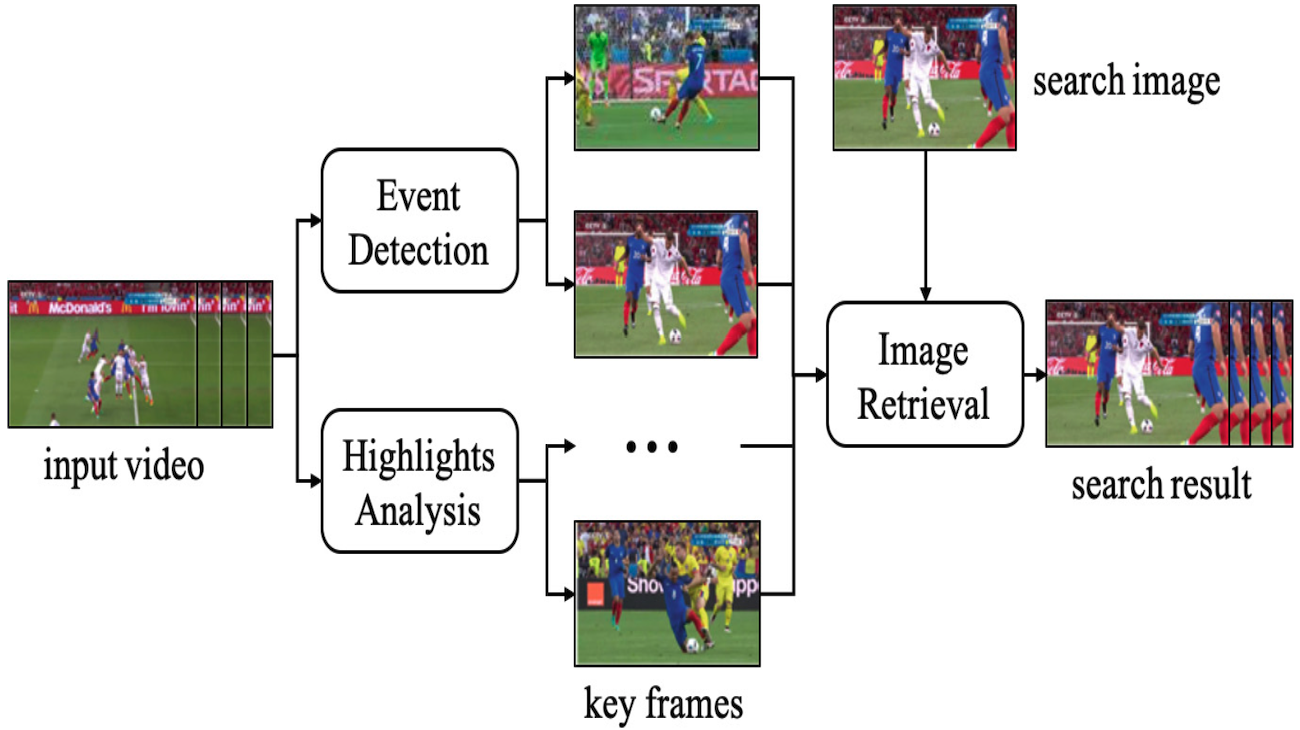 | Fine-Grain Level Sports Video Search Engine Zikai Song, Junqing Yu, Hengyou Cai, Yangliu Hu, Yi-Ping Phoebe Chen MultiMedia Modeling, 2020 paper We designed and developed a sports video search engine based on distributed architecture, aimimng to provide content-based video analysis and retrieval services |
 | SSET: a dataset for shot segmentation, event detection, player tracking in soccer videos Na Feng, Zikai Song, Junqing Yu, Yi-Ping Phoebe Chen, Yizhu Zhao, Yunfeng He, Tao Guan Multimedia Tools and Applications, 2020 Project Page / Paper We construct a soccer dataset named Soccer Dataset for Shot, Event, and Tracking, to meet the research needs of shot segmentation, event detection and player tracking |
 | Comprehensive dataset of broadcast soccer videos Junqing Yu, Aiping Lei, Zikai Song, Tingting Wang, Hengyou Cai, Na Feng MIPR, 2018 project / paper We focus on broadcast soccer videos and present a comprehensive dataset for analysis, including shot boundaries, event annotations, and bounding boxes. |
Project
- 2023 入选国家资助博士后计划
- 2024 主持中国博士后面上项目
- 2024 主持国自然青年基金项目
- 2024 主持湖北省博新计划项目
- 2025 主持中国博士后特别资助项目
- 2025 入选CSC国家公派博士后项目